Big Data
Aprovechar el poder del Big Data y ofrecer la experiencia de los líderes tecnológicos para resolver eficazmente el dilema de datos con soluciones de vanguardia. Siendo el primer Partner en implementar un Big Data desde el Hardware, Software y la automatización de los datos hacia el lago de datos con productos Oracle.
Nuestro proceso de trabajo
No basamos en un marco metodológico, en este caso Innmon o Kimbal, en los cuales se realizan los siguientes procesos de manera general:
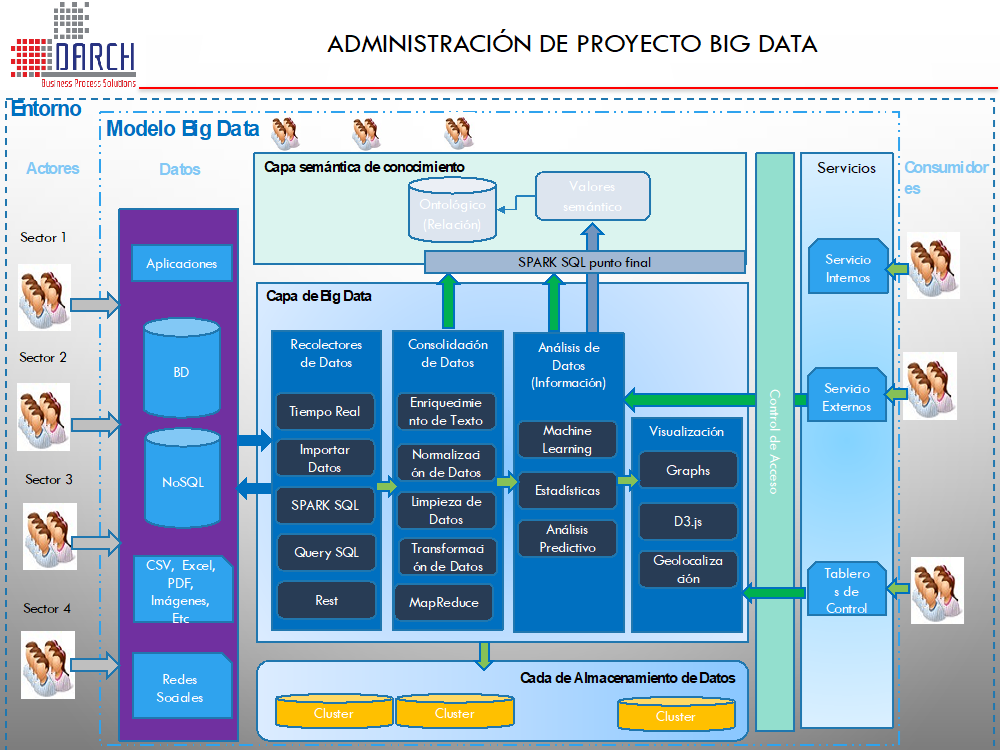
- Definir la estrategia de Big Data y Necesidades de Negocio.
- Elegir fuentes de datos.
- Adquirir e ingerir fuentes de datos.
- Desarrollar hipótesis y métodos.
- Integrar / alinear datos para el análisis.
- Explorar datos usando modelos.
- Desplegar y monitorear.
Características del Servicio
Los servicios implementan los siguientes componentes como resultado de los trabajos.
- Lago de Datos: Para establecer un inventario de lo que está en un lago de datos, es crítico administrar los metadatos a medida que se ingieren los datos. Para comprender cómo se asocian o conectan los datos en un lago de datos. Los arquitectos de datos o los ingenieros de datos a menudo usan claves únicas u otras técnicas (modelos semánticos, modelos de datos, etc.) para que los científicos de datos y otros desarrolladores de visualización sepan cómo usar la información almacenada dentro del lago de datos.
- Machine Learning: Explora la construcción y el estudio de algoritmos de aprendizaje. Se puede ver como una unión de métodos de aprendizaje no supervisados (más comúnmente conocidos como minería de datos), y métodos de aprendizaje supervisados profundamente arraigados en la teoría matemática, específicamente estadística, combinatoria y optimización. Ahora se está formando una tercera rama llamada aprendizaje de refuerzo, donde se gana el rendimiento de los objetivos, pero no se reconoce específicamente por el docente, por ejemplo, manejar un vehículo. Las máquinas de programación para aprender rápidamente de las consultas y adaptarse a conjuntos de datos cambiantes condujeron a un campo completamente nuevo dentro de Big Data denominado aprendizaje automático. Se ejecutan los procesos y se almacenan los resultados que luego se usan en las ejecuciones subsiguientes para informar de forma iterativa el proceso y refinar los resultados.
- Análisis de Sentimiento: El monitoreo de medios y el análisis de texto son métodos automatizados para recuperar información de datos grandes no estructurados o semiestructurados, como datos de transacciones, redes sociales, blogs y sitios web de noticias. Esto se usa para comprender lo que las personas dicen y sienten sobre las marcas, productos o servicios u otros tipos de temas. Usando el procesamiento de lenguaje natural (NLP) o analizando frases u oraciones, el análisis semántico puede detectar el sentimiento y también revelar cambios en el sentimiento para predecir posibles escenarios.
Somos Partner de Oracle, Cloudera y SAS para la implementación de los diferentes servicios.